Karate UI
UI Test Automation Made Simple.
Hello World
Index
Capabilities
- Simple, clean syntax that is well suited for people new to programming or test-automation
- All-in-one framework that includes parallel-execution, HTML reports, environment-switching, Visual Testing, and CI integration
- Cross-platform - with even the option to run as a programming-language neutral stand-alone executable
- Support for
iframe-s, switching tabs, multiple URL domains, and uploading files - No need to learn complicated programming concepts such as “callbacks”, “
async/await” and “promises” - Option to use wildcard and “friendly” locators without needing to inspect the HTML-page source, CSS, or internal XPath structure
- Chrome-native automation using the Chrome DevTools Protocol (equivalent to Puppeteer)
- W3C WebDriver support built-in, which can also use remote / grid providers
- Cross-Browser support including Microsoft Edge on Windows and Safari on Mac
- Playwright support (experimental) for even more cross-browser and headless options, that can connect to a server or Docker container using the Playwright wire-protocol
- Parallel execution on a single node, cloud-CI environment or Docker - without needing a “master node” or “grid”
- Embed video-recordings of tests into the HTML report from a Docker container
- [experimental] Android and iOS mobile support via Appium
- Seamlessly mix API and UI tests within the same script, for example sign-in using an API and speed-up your tests
- Intercept HTTP requests made by the browser and re-use Karate mocks to stub / modify server responses and even replace HTML content
- Use the power of Karate’s
matchassertions and core capabilities for UI assertions - Simple retry and wait strategy, no need to graduate from any test-automation university to understand the difference between “implicit waits”, “explicit waits” and “fluent waits” :)
- Simpler, elegant, and DRY alternative to the so-called “Page Object Model” pattern
- Carefully designed fluent-API to handle common combinations such as a
submit()+click()action - Elegant syntax for typical web-automation challenges such as waiting for a page-load or element to appear
- Execute JavaScript in the browser with one-liners - for example to get data out of an HTML table
- Compose re-usable functions based on your specific environment or application needs
- Comprehensive support for user-input types including key-combinations and
mouse()actions - Step-debug and even “go back in time” to edit and re-play steps - using the unique, innovative Karate Extension for Visual Studio Code
- Traceability: detailed wire-protocol logs can be enabled in-line with test-steps in the HTML report
- Convert HTML to PDF and capture the entire (scrollable) web-page as an image using the Chrome Java API
Comparison
To understand how Karate compares to other UI automation frameworks, this article can be a good starting point: The world needs an alternative to Selenium - so we built one.
Examples
Web Browser
- Example 1 - simple example that navigates to GitHub and Google Search
- Example 2 - simple but very relevant and meaty example (see video) that shows how to
- wait for page-navigation
- use a friendly wildcard locator
- wait for an element to be ready
- compose functions for elegant custom “wait” logic
- assert on tabular results in the HTML
- Example 3 - which is a single modular script that exercises all capabilities of Karate Driver
- a handy reference that can give you ideas on how to structure your tests
- run as part of Karate’s regression suite via GitHub Actions
Mobile / Appium
Please consider Mobile support as experimental. But we are very close and there are some teams that use Karate for simple use-cases. Please contribute code if you can.
- Refer to this example project
Windows
- Example - but also see the
karate-robotfor an alternative approach.
Driver Configuration
configure driver
This below declares that the native (direct) Chrome integration should be used, on both Mac OS and Windows - from the default installed location.
* configure driver = { type: 'chrome' }
If you want to customize the start-up, you can use a batch-file:
* configure driver = { type: 'chrome', executable: 'chrome' }
Here a batch-file called chrome can be placed in the system PATH (and made executable) with the following contents:
"/Applications/Google Chrome.app/Contents/MacOS/Google Chrome" $*
For Windows it would be chrome.bat in the system PATH as follows:
"C:\Program Files (x86)\Google\Chrome\Application\chrome" %*
Another example for WebDriver, again assuming that chromedriver is in the PATH:
{ type: 'chromedriver', port: 9515, executable: 'chromedriver' }
| key | description |
|---|---|
type | see driver types |
executable | if present, Karate will attempt to invoke this, if not in the system PATH, you can use a full-path instead of just the name of the executable. batch files should also work |
start | default true, Karate will attempt to start the executable - and if the executable is not defined, Karate will even try to assume the default for the OS in use |
stop | optional, defaults to true very rarely needed, only in cases where you want the browser to remain open after your tests have completed, typically when you write a custom Target |
port | optional, and Karate would choose the “traditional” port for the given type |
host | optional, will default to localhost and you normally never need to change this |
pollAttempts | optional, will default to 20, you normally never need to change this (and changing pollInterval is preferred), and this is the number of attempts Karate will make to wait for the port to be ready and accepting connections before proceeding |
pollInterval | optional, will default to 250 (milliseconds) and you normally never need to change this (see pollAttempts) unless the driver executable takes a very long time to start |
headless | headless mode only applies to { type: 'chrome' } for now, also see DockerTarget and webDriverSession |
showDriverLog | default false, will include webdriver HTTP traffic in Karate report, useful for troubleshooting or bug reports |
showProcessLog | default false, will include even executable (webdriver or browser) logs in the Karate report |
showBrowserLog | default true, only applies to { type: 'chrome' } which shows the browser console log in the HTML report for convenience |
addOptions | default null, has to be a list / JSON array that will be appended as additional CLI arguments to the executable, e.g. ['--no-sandbox', '--windows-size=1920,1080'] |
beforeStart | default null, an OS command that will be executed before commencing a Scenario (and before the executable is invoked if applicable) typically used to start video-recording |
afterStop | default null, an OS command that will be executed after a Scenario completes, typically used to stop video-recording and save the video file to an output folder |
videoFile | default null, the path to the video file that will be added to the end of the test report, if it does not exist, it will be ignored |
httpConfig | optional, and typically only used for remote WebDriver usage where the HTTP client configuration needs to be tweaked, e.g. { readTimeout: 120000 } (also see timeout below) |
timeout | default 30000, amount of time (in milliseconds) that type chrome will wait for an operation that takes time (typically navigating to a new page) - and as a convenience for WebDriver, this will be equivalent to setting the readTimeout for the httpConfig (see above) - also see timeout() |
playwrightUrl | only applies for { type: 'playwright', start: false }, the Playwright wire-protocol (websockets) server URL, also see playwrightOptions |
playwrightOptions | optional, see playwrightOptions |
webDriverUrl | see webDriverUrl |
webDriverSession | see webDriverSession |
webDriverPath | optional, and rarely used only in case you need to append a path such as /wd/hub - typically needed for Appium (or a Selenium Grid) on localhost, where host, port / executable etc. are involved. |
highlight | default false, useful for demos or for running a test in “slow motion” where before each navigation action, the HTML element for the current locator is highlighted for a duration of highlightDuration |
highlightDuration | default 3000 (milliseconds), duration to apply the highlight |
attach | optional, only for type: 'chrome' and start: false when you want to attach to an existing page in a Chrome DevTools session, uses a “contains” match against the URL |
userDataDir | optional, by default Karate will auto-create a user dir for Chrome and other browsers, but if you want to provide the path to an existing folder (which can reduce disk space usage in some situations), note that for Chrome, this will pass the command line option --user-data-dir. if null, Chrome will use the system defaults (the --user-data-dir command-line option will not be passed) |
For more advanced options such as for Docker, CI, headless, cloud-environments or custom needs, see configure driverTarget.
webDriverUrl
Karate implements the W3C WebDriver spec, which means that you can point Karate to a remote “grid” such as Zalenium or a SaaS provider such as the AWS Device Farm. The webDriverUrl driver configuration key is optional, but if specified, will be used as the W3C WebDriver remote server. Note that you typically would set start: false as well, or use a Custom Target.
For example, once you run the couple of Docker commands to get Zalenium running, you can do this:
* configure driver = { type: 'chromedriver', start: false, webDriverUrl: 'http://localhost:4444/wd/hub' }
Note that you can add showDriverLog: true to the above for troubleshooting if needed. You should be able to run tests in parallel with ease !
webDriverSession
When targeting a W3C WebDriver implementation, either as a local executable or Remote WebDriver, you can specify the JSON that will be passed as the payload to the Create Session API. The most important part of this payload is the capabilities. It will default to { browserName: '<name>' } for convenience where <name> will be chrome, firefox etc.
So most of the time this would be sufficient:
* configure driver = { type: 'chromedriver' }
Since it will result in the following request to the WebDriver /session:
{"capabilities":{"alwaysMatch":{"browserName":"chrome"}}}
But in some cases, especially when you need to talk to remote driver instances, you need to pass specific “shapes” of JSON expected by the particular implementation - or you may need to pass custom data or “extension” properties. Use the webDriverSession property in those cases.
Note:
desiredCapabilitieshas been deprecated and not recommended for use.
For example:
* def session = { capabilities: { alwaysMatch: { browserName: 'chrome', 'goog:chromeOptions': { args: [ '--headless', 'window-size=1280,720' ] } } } }
* configure driver = { type: 'chromedriver', webDriverSession: '#(session)', start: false, webDriverUrl: 'http://localhost:9515/wd/hub' }
Another example is that for the new Microsoft Edge browser (based on Chromium), the Karate default alwaysMatch is not supported, so this is what works:
* configure driver = { type: 'msedgedriver', webDriverSession: { capabilities: { browserName: 'edge' } } }
Here are some of the things that you can customize, but note that these depend on the driver implementation.
proxyacceptInsecureCertsmoz:firefoxOptions- e.g. for headless FireFox
Note that some capabilities such as “headless” may be possible via the command-line to the local executable, so using addOptions may work instead.
Also see driver.sessionId.
Playwright
Driver that leverages Playwright java native APIs.
To use it, add the following dependency:
<dependency>
<groupId>io.karate</groupId>
<artifactId>karate-playwright</artifactId>
<scope>test</scope>
</dependency>
And make sure it is declared before io.karate:karate-core.
A server will be automatically started and made available to Karate without any extra-script. If you have one pre-started, you can still use the playwrightUrl driver config.
playwrightOptions
When using Playwright you can omit this in which case Karate will default to Chrome (within Playwright) and the default browser window size.
This can take the following keys:
browserType- defaults tochromium, can be set to the other types that Playwright supports, e.g.firefoxandwebkitcontext- JSON which will be passed as the argument of the Playwrightbrowser.newContext()call, needed typically to set the page dimensionschannel- defaults to chrome, for thechromiumbrowserType, allows to specify which flavor to useinstallBrowsers- defaults totrue, whether or not all the supported browsers will be downloaded and installed by Playwright (once).
Note that there is a top-level config flag for headless mode. The default is: * configure driver = { headless: false }
Playwright Legacy
To use Playwright, you need to start a Playwright server. If you have one pre-started, you need to use the playwrightUrl driver config.
Or you can set up an executable that can do it and log the URL to the console when the server is ready. The websocket URL will look like this: ws://127.0.0.1:4444/0e0bd1c0bb2d4eb550d02c91046dd6e0.
Here’s a simple recipe to set up this mechanism on your local machine. NodeJS is a pre-requisite and you can choose a folder (e.g. playwright) for the “start scripts” to live. Within that folder, you can run:
npm i -D playwright
Now create a file called playwright/server.js with the following code:
const playwright = require('playwright');
const port = process.argv[2] || 4444;
const browserType = process.argv[3] || 'chromium';
const headless = process.argv[4] == 'true';
console.log('using port:', port, 'browser:', browserType, 'headless:', headless);
const serverPromise = playwright[browserType].launchServer({ headless: headless, port: port });
serverPromise.then(bs => console.log(bs.wsEndpoint()));
The main thing here is that the server URL should be logged to the console when it starts. Karate will scan the log for any string that starts with ws:// and kick things off from there.
Also Karate will call the executable with three arguments in this order:
portbrowserTypeheadless
So this is how you can communicate your cross-browser config from your Karate test to the executable.
The final piece of the puzzle is to set up a batch file to start the server:
#!/bin/bash
exec node /some/path/playwright/server.js $*
The exec is important here so that Karate can stop the node process cleanly.
Now you can use the path of the batch file in the driver executable config.
* configure driver = { type: 'playwright', executable: 'path/to/start-server' }
For convenience, Karate assumes by default that the executable name is playwright and that it exists in the System PATH. Make sure that the batch file is made executable depending on your OS.
Based on the above details, you should be able to come up with a custom strategy to connect Karate to Playwright. And you can consider a driverTarget approach for complex needs such as using a Docker container for CI.
configure driverTarget
The configure driver options are fine for testing on “localhost” and when not in headless mode. But when the time comes for running your web-UI automation tests on a continuous integration server, things get interesting. To support all the various options such as Docker, headless Chrome, cloud-providers etc., Karate introduces the concept of a pluggable Target where you just have to implement two methods:
public interface Target {
Map<String, Object> start(com.intuit.karate.core.ScenarioRuntime sr);
Map<String, Object> stop(com.intuit.karate.core.ScenarioRuntime sr);
}
-
start(): TheMapreturned will be used as the generated driver configuration. And thestart()method will be invoked as soon as anyScenariorequests for a web-browser instance (for the first time) via thedriverkeyword. -
stop(): Karate will call this method at the end of every top-levelScenario(that has not beencall-ed by anotherScenario).
If you use the provided ScenarioRuntime.logger instance in your Target code, any logging you perform will nicely appear in-line with test-steps in the HTML report, which is great for troubleshooting or debugging tests.
Combined with Docker, headless Chrome and Karate’s parallel-execution capabilities - this simple start() and stop() lifecycle can effectively run web UI automation tests in parallel on a single node.
DockerTarget
Karate has a built-in implementation for Docker (DockerTarget) that supports 2 existing Docker images out of the box:
justinribeiro/chrome-headless- for Chrome “native” in headless modekaratelabs/karate-chrome- for Chrome “native” but with an option to connect to the container and view via VNC, and with video-recording
To use either of the above, you do this in a Karate test:
* configure driverTarget = { docker: 'justinribeiro/chrome-headless', showDriverLog: true }
Or for more flexibility, you could do this in karate-config.js and perform conditional logic based on karate.env. One very convenient aspect of configure driverTarget is that if in-scope, it will over-ride any configure driver directives that exist. This means that you can have the below snippet activate only for your CI build, and you can leave your feature files set to point to what you would use in “dev-local” mode.
function fn() {
var config = {
baseUrl: 'https://qa.mycompany.com'
};
if (karate.env == 'ci') {
karate.configure('driverTarget', { docker: 'karatelabs/karate-chrome' });
}
return config;
}
To use the recommended --security-opt seccomp=chrome.json Docker option, add a secComp property to the driverTarget configuration. And if you need to view the container display via VNC, set the vncPort to map the port exposed by Docker.
karate.configure('driverTarget', { docker: 'karatelabs/karate-chrome', secComp: 'src/test/java/chrome.json', vncPort: 5900 });
Custom Target
If you have a custom implementation of a Target, you can easily construct any custom Java class and pass it to configure driverTarget. Here below is the equivalent of the above, done the “hard way”:
var DockerTarget = Java.type('com.intuit.karate.driver.DockerTarget');
var options = { showDriverLog: true };
var target = new DockerTarget(options);
target.command = function(port){ return 'docker run -d -p '
+ port + ':9222 --security-opt seccomp=./chrome.json justinribeiro/chrome-headless' };
karate.configure('driverTarget', target);
The built-in DockerTarget is a good example of how to:
- perform any pre-test set-up actions
- provision a free port and use it to shape the
start()command dynamically - execute the command to start the target process
- perform an HTTP health check to wait until we are ready to receive connections
- and when
stop()is called, indicate if a video recording is present (after retrieving it from the stopped container)
Controlling this flow from Java can take a lot of complexity out your build pipeline and keep things cross-platform. And you don’t need to line-up an assortment of shell-scripts to do all these things. You can potentially include the steps of deploying (and un-deploying) the application-under-test using this approach - but probably the top-level JUnit test-suite would be the right place for those.
If the machine where you are running Karate is not the same as your target host (e.g. a sibling Docker container or a Chrome browser in a different machine) you might need to configure DockerTarget with the remoteHost and/or useDockerHost properties. The DockerTarget implementation has an example and you can find more details here.
Another (simple) example of a custom Target you can use as a reference is this one: karate-devicefarm-demo - which demonstrates how Karate can be used to drive tests on AWS DeviceFarm. The same approach should apply to any Selenium “grid” provider such as Zalenium.
karate-chrome
The karate-chrome Docker is an image created from scratch, using a Java / Maven image as a base and with the following features:
- Chrome in “full” mode (non-headless)
- Chrome DevTools protocol exposed on port 9222
- VNC server exposed on port 5900 so that you can watch the browser in real-time
- a video of the entire test is saved to
/tmp/karate.mp4 - after the test, when
stop()is called, theDockerTargetwill embed the video into the HTML report (expand the last step in theScenarioto view)
To try this or especially when you need to investigate why a test is not behaving properly when running within Docker, these are the steps:
- start the container:
docker run --name karate --rm -p 9222:9222 -p 5900:5900 -e KARATE_SOCAT_START=true --cap-add=SYS_ADMIN karatelabs/karate-chrome- it is recommended to use
--security-opt seccomp=chrome.jsoninstead of--cap-add=SYS_ADMIN
- point your VNC client to
localhost:5900(password:karate)- for example on a Mac you can use this command:
open vnc://localhost:5900
- for example on a Mac you can use this command:
- run a test using the following
driverconfiguration, and this is one of the few times you would ever need to set thestartflag tofalse* configure driver = { type: 'chrome', start: false, showDriverLog: true }
- you can even use the Karate VS Code extension to debug and step-through a test
- if you omit the
--rmpart in the start command, after stopping the container, you can dump the logs and video recording using this command (here.stands for the current working folder, change it if needed):docker cp karate:/tmp .- this would include the
stderrandstdoutlogs from Chrome, which can be helpful for troubleshooting
For more information on the Docker containers for Karate and how to use them, refer to the wiki: Docker.
Driver Types
The recommendation is that you prefer chrome for development, and once you have the tests running smoothly - you can switch to a different WebDriver implementation.
| type | default port | default executable | description |
|---|---|---|---|
chrome | 9222 | mac: /Applications/Google Chrome.app/Contents/MacOS/Google Chrome win: C:/Program Files (x86)/Google/Chrome/Application/chrome.exe | “native” Chrome automation via the DevTools protocol |
playwright | 4444 | playwright | see playwrightOptions and Playwright |
msedge | 9222 | mac: /Applications/Microsoft Edge.app/Contents/MacOS/Microsoft Edge win: C:/Program Files (x86)/Microsoft/Edge/Application/msedge.exe | the new Chromium based Microsoft Edge, using the DevTools protocol |
chromedriver | 9515 | chromedriver | W3C Chrome Driver |
geckodriver | 4444 | geckodriver | W3C Gecko Driver (Firefox) |
safaridriver | 5555 | safaridriver | W3C Safari Driver |
msedgedriver | 9515 | msedgedriver | W3C Microsoft Edge WebDriver (the new one based on Chromium), also see webDriverSession |
mswebdriver | 17556 | MicrosoftWebDriver | Microsoft Edge “Legacy” WebDriver |
iedriver | 5555 | IEDriverServer | IE (11 only) Driver |
winappdriver | 4727 | C:/Program Files (x86)/Windows Application Driver/WinAppDriver | Windows Desktop automation, similar to Appium |
android | 4723 | appium | android automation via Appium |
ios | 4723 | appium | iOS automation via Appium |
Distributed Testing
Karate can split a test-suite across multiple machines or Docker containers for execution and aggregate the results. Please refer to the wiki: Distributed Testing.
Locators
The standard locator syntax is supported. For example for web-automation, a / prefix means XPath and else it would be evaluated as a “CSS selector”.
And input('input[name=someName]', 'test input')
When submit().click("//input[@name='commit']")
| platform | prefix | means | example |
|---|---|---|---|
| web | (none) | css selector | input[name=someName] |
| web android ios | / | xpath | //input[@name='commit'] |
| web | {} | exact text content | {a}Click Me |
| web | {^} | partial text content | {^a}Click Me |
| win android ios | (none) | name | Submit |
| win android ios | @ | accessibility id | @CalculatorResults |
| win android ios | # | id | #MyButton |
| ios | : | -ios predicate string | :name == 'OK' type == XCUIElementTypeButton |
| ios | ^ | -ios class chain | ^**/XCUIElementTypeTable[name == 'dataTable'] |
| android | - | -android uiautomator | -input[name=someName] |
Wildcard Locators
The “{}” and “{^}” locator-prefixes are designed to make finding an HTML element by text content super-easy. You will typically also match against a specific HTML tag (which is preferred, and faster at run-time). But even if you use “{*}” (or “{}” which is the equivalent short-cut) to match any tag, you are selecting based on what the user sees on the page.
When you use CSS and XPath, you need to understand the internal CSS class-names and XPath structure of the page. But when you use the visible text-content, for example the text within a <button> or hyperlink (<a>), performing a “selection” can be far easier. And this kind of locator is likely to be more stable and resistant to cosmetic changes to the underlying HTML.
You have the option to adjust the “scope” of the match, and here are examples:
| Locator | Description |
|---|---|
click('{a}Click Me') | the first <a> where the text-content is exactly: Click Me |
click('{}Click Me') | the first element (any tag name) where the text-content is exactly: Click Me |
click('{^}Click') | the first element (any tag name) where the text-content contains: Click |
click('{^span}Click') | the first <span> where the text-content contains: Click |
click('{div:2}Click Me') | the second <div> where the text-content is exactly: Click Me |
click('{span/a}Click Me') | the first <a> where a <span> is the immediate parent, and where the text-content is exactly: Click Me |
click('{^*:4}Me') | the fourth HTML element (of any tag name) where the text-content contains: Me |
Note that “{:4}” can be used as a short-cut instead of “{*:4}”.
You can experiment by using XPath snippets like the “span/a” seen above for even more “narrowing down”, but try to expand the “scope modifier” (the part within curly braces) only when you need to do “de-duping” in case the same user-facing text appears multiple times on a page.
Friendly Locators
The “wildcard” locators are great when the human-facing visible text is within the HTML element that you want to interact with. But this approach doesn’t work when you have to deal with data-entry and <input> fields. This is where the “friendly locators” come in. You can ask for an element by its relative position to another element which is visible - such as a <span>, <div> or <label> and for which the locator is easy to obtain.
Also see Tree Walking.
| Method | Finds Element |
|---|---|
rightOf() | to right of given locator |
leftOf() | to left of given locator |
above() | above given locator |
below() | below given locator |
near() | near given locator in any direction |
The above methods return a chainable Finder instance. For example if you have HTML like this:
<input type="checkbox"><span>Check Three</span>
To click on the checkbox, you just need to do this:
* leftOf('{}Check Three').click()
By default, the HTML tag that will be searched for will be input. While rarely needed, you can over-ride this by calling the find(tagName) method like this:
* rightOf('{}Some Text').find('span').click()
One more variation supported is that instead of an HTML tag name, you can look for the textContent:
* rightOf('{}Some Text').find('{}Click Me').click()
One thing to watch out for is that the “origin” of the search will be the mid-point of the whole HTML element, not just the text. So especially when doing above() or below(), ensure that the “search path” is aligned the way you expect. If you get stuck trying to align the search path, especially if the “origin” is a small chunk of text that is aligned right or left - try near().
In addition to <input> fields, <select> boxes are directly supported like this, so internally a find('select') is “chained” automatically:
* below('{}State').select(0)
rightOf()
* rightOf('{}Input On Right').input('input right')
leftOf()
* leftOf('{}Input On Left').clear().input('input left')
above()
* above('{}Input On Right').click()
below()
* below('{}Input On Right').input('input below')
near()
One reason why you would need near() is because an <input> field may either be on the right or below the label depending on whether the “container” element had enough width to fit both on the same horizontal line. Of course this can be useful if the element you are seeking is diagonally offset from the locator you have.
* near('{}Go to Page One').click()
Visual Testing
See compareImage.
Keywords
Only one keyword sets up UI automation in Karate, typically by specifying the URL to open in a browser. And then you would use the built-in driver JS object for all other operations, combined with Karate’s match syntax for assertions where needed.
driver
Navigates to a new page / address. If this is the first instance in a test, this step also initializes the driver instance for all subsequent steps - using what is configured.
Given driver 'https://github.com/login'
And yes, you can use variable expressions from karate-config.js. For example:
* driver webUrlBase + '/page-01'
As seen above, you don’t have to force all your steps to use the
Given,When,ThenBDD convention, and you can just use “*” instead.
driver JSON
A variation where the argument is JSON instead of a URL / address-string, used typically if you are testing a desktop (or mobile) application. This example is for Windows, and you can provide the app, appArguments and other parameters expected by the WinAppDriver via the webDriverSession. For example:
* def session = { desiredCapabilities: { app: 'Microsoft.WindowsCalculator_8wekyb3d8bbwe!App' } }
Given driver { webDriverSession: '#(session)' }
So this is just for convenience and readability, using configure driver can do the same thing like this:
* def session = { desiredCapabilities: { app: 'Microsoft.WindowsCalculator_8wekyb3d8bbwe!App' } }
* configure driver = { webDriverSession: '#(session)' }
Given driver {}
This design is so that you can use (and data-drive) all the capabilities supported by the target driver - which can vary a lot depending on whether it is local, remote, for desktop or mobile etc.
Syntax
The built-in driver JS object is where you script UI automation. It will be initialized only after the driver keyword has been used to navigate to a web-page (or application).
You can refer to the Java interface definition of the driver object to better understand what the various operations are. Note that Map<String, Object> translates to JSON, and JavaBean getters and setters translate to JS properties - e.g. driver.getTitle() becomes driver.title.
Methods
As a convenience, all the methods on the driver have been injected into the context as special (JavaScript) variables so you can omit the “driver.” part and save a lot of typing. For example instead of:
And driver.input('#eg02InputId', Key.SHIFT)
Then match driver.text('#eg02DivId') == '16'
You can shorten all that to:
And input('#eg02InputId', Key.SHIFT)
Then match text('#eg02DivId') == '16'
When it comes to JavaBean getters and setters, you could call them directly, but the driver.propertyName form is much better to read, and you save the trouble of typing out round brackets. So instead of doing this:
And match getUrl() contains 'page-01'
When setUrl(webUrlBase + '/page-02')
You should prefer this form, which is more readable:
And match driver.url contains 'page-01'
When driver.url = webUrlBase + '/page-02'
Note that to navigate to a new address you can use driver - which is more concise.
Chaining
All the methods that return the following Java object types are “chain-able”. This means that you can combine them to concisely express certain types of “intent” - without having to repeat the locator.
For example, to retry() until an HTML element is present and then click() it:
# retry returns a "Driver" instance
* retry().click('#someId')
Or to wait until a button is enabled using the default retry configuration:
# waitForEnabled() returns an "Element" instance
* waitForEnabled('#someBtn').click()
Or to temporarily over-ride the retry configuration and wait:
* retry(5, 10000).waitForEnabled('#someBtn').click()
Or to move the mouse() to a given [x, y] co-ordinate and perform a click:
* mouse(100, 200).click()
Or to use Friendly Locators:
* rightOf('{}Input On Right').input('input right')
Also see waits.
Syntax
driver.url
Get the current URL / address for matching. Example:
Then match driver.url == webUrlBase + '/page-02'
Note that if you do this as soon as you navigate to a new page, there is a chance that this returns the old / stale URL. To avoid “flaky” tests, use waitForUrl()
This can also be used as a “setter” to navigate to a new URL during a test. But always use the driver keyword when you start a test and you can choose to prefer that shorter form in general.
* driver.url = 'http://localhost:8080/test'
driver.title
Get the current page title for matching. Example:
Then match driver.title == 'Test Page'
Note that if you do this immediately after a page-load, in some cases you need to wait for the page to fully load. You can use a waitForUrl() before attempting to access driver.title to make sure it works.
driver.dimensions
Set the size of the browser window:
And driver.dimensions = { x: 0, y: 0, width: 300, height: 800 }
This also works as a “getter” to get the current window dimensions.
* def dims = driver.dimensions
The result JSON will be in the form: { x: '#number', y: '#number', width: '#number', height: '#number' }
position()
Get the absolute position and size of an element by locator as follows:
* def pos = position('#someid')
The absolute position returns the coordinate from the top left corner of the page. If you need the position of an element relative to the current viewport, you can pass an extra boolean argument set to ‘true’ (‘false’ will return the absolute position) :
* def pos = position('#someid', true)
The result JSON will be in the form: { x: '#number', y: '#number', width: '#number', height: '#number' }
input()
2 string arguments: locator and value to enter.
* input('input[name=someName]', 'test input')
As a convenience, there is a second form where you can pass an array as the second argument:
* input('input[name=someName]', ['test', ' input', Key.ENTER])
And an extra convenience third argument is a time-delay (in milliseconds) that will be applied before each array value. This is sometimes needed to “slow down” keystrokes, especially when there is a lot of JavaScript or security-validation behind the scenes.
* input('input[name=someName]', ['a', 'b', 'c', Key.ENTER], 200)
And for extra convenience, you can pass a string as the second argument above, in which case Karate will split the string and fire the delay before each character:
* input('input[name=someName]', 'type this slowly', 100)
If you need to send input to the “whole page” (not a specific input field), just use body as the selector:
* input('body', Key.ESCAPE)
Special Keys
Special keys such as ENTER, TAB etc. can be specified like this:
* input('#someInput', 'test input' + Key.ENTER)
A special variable called Key will be available and you can see all the possible key codes here.
Also see value(locator, value) and clear()
submit()
Karate has an elegant approach to handling any action such as click() that results in a new page load. You “signal” that a submit is expected by calling the submit() function (which returns a Driver object) and then “chaining” the action that is expected to trigger a page load.
When submit().click('*Page Three')
The advantage of this approach is that it works with any of the actions. So even if your next step is the ENTER key, you can do this:
When submit().input('#someform', Key.ENTER)
Karate will do the best it can to detect a page change and wait for the load to complete before proceeding to any step that follows.
You can even mix this into mouse() actions.
For some SPAs (Single Page Applications) the detection of a “page load” may be difficult because page-navigation (and the browser history) is taken over by JavaScript. In such cases, you can always fall-back to a waitForUrl() or a more generic waitFor().
waitForUrl() instead of submit()
Sometimes, because of an HTTP re-direct, it can be difficult for Karate to detect a page URL change, or it will be detected too soon, causing your test to fail. In such cases, you can use waitForUrl().
Note that it uses a string “contains” match, so you just need to supply a portion of the URL you are expecting.
So instead of this, which uses submit():
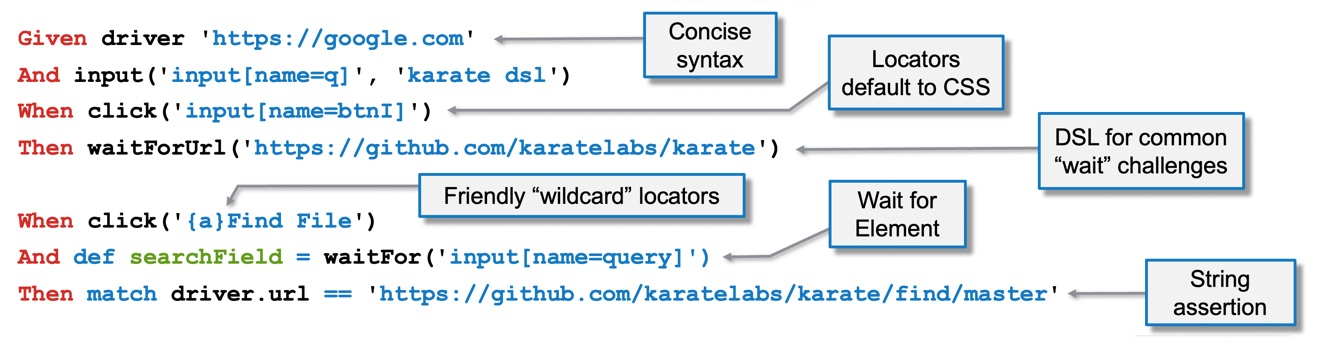
Given driver 'https://google.com'
And input('textarea[name=q]', 'karate dsl')
When submit().click('input[name=btnI]')
Then match driver.url == 'https://github.com/karatelabs/karate'
You can do this. Note that waitForUrl() will also act as an assertion, so you don’t have to do an extra match.
Given driver 'https://google.com'
And input('textarea[name=q]', 'karate dsl')
When click('input[name=btnI]')
And waitForUrl('https://github.com/karatelabs/karate')
And you can even chain a retry() before the waitForUrl() if you know that it is going to take a long time:
And retry(5, 10000).waitForUrl('https://github.com/karatelabs/karate')
waitFor() instead of submit()
This is very convenient to use for the first element you need to interact with on a freshly-loaded page. It can be used instead of waitForUrl() and you can still perform a page URL assertion as seen below.
Here is an example of waiting for a search box to appear after a click(), and note how we re-use the Element reference returned by waitFor() to proceed with the flow. We even slip in a page-URL assertion without missing a beat.
When click('{a}Find File')
And def search = waitFor('input[name=query]')
Then match driver.url == 'https://github.com/karatelabs/karate/find/master'
Given search.input('karate-logo.png')
Of course if you did not care about the page URL assertion (you can still do it later), you could do this
waitFor('input[name=query]').input('karate-logo.png')
delay()
Of course, resorting to a “sleep” in a UI test is considered a very bad-practice and you should always use retry() instead. But sometimes it is un-avoidable, for example to wait for animations to render - before taking a screenshot. The nice thing here is that it returns a Driver instance, so you can chain any other method and the “intent” will be clear. For example:
* delay(1000).screenshot()
The other situation where we have found a delay() un-avoidable is for some super-secure sign-in forms - where a few milliseconds delay before hitting the submit button is needed.
click()
Just triggers a click event on the DOM element:
* click('input[name=someName]')
Also see submit() and mouse().
select()
You can use this for plain-vanilla <select> boxes that have not been overly “enhanced” by JavaScript. Nowadays, most “select” (or “multi-select”) user experiences are JavaScript widgets, so you would be needing to fire a click() or two to get things done. But if you are really dealing with an HTML <select>, then read on.
There are four variations and use the locator prefix conventions for exact and contains matches against the <option> text-content.
# select by displayed text
Given select('select[name=data1]', '{}Option Two')
# select by partial displayed text
And select('select[name=data1]', '{^}Two')
# select by `value`
Given select('select[name=data1]', 'option2')
# select by index
Given select('select[name=data1]', 2)
If you have trouble with <select> boxes, try using script() to execute custom JavaScript within the page as a work-around.
focus()
* focus('.myClass')
clear()
* clear('#myInput')
If this does not work, try value(selector, value).
scroll()
Scrolls to the element.
* scroll('#myInput')
Since a scroll() + click() (or input()) is a common combination, you can chain these:
* scroll('#myBtn').click()
* scroll('#myTxt').input('hello')
mouse()
This returns an instance of Mouse on which you can chain actions. A common need is to move (or hover) the mouse, and for this you call the move() method.
The mouse().move() method has two forms. You can pass 2 integers as the x and y co-ordinates or you can pass the locator string of the element to move to. Make sure you call go() at the end - if the last method in the chain is not click() or up().
* mouse().move(100, 200).go()
* mouse().move('#eg02RightDivId').click()
# this is a "click and drag" action
* mouse().down().move('#eg02LeftDivId').up()
You can even chain a submit() to wait for a page load if needed:
* mouse().move('#menuItem').submit().click();
Since moving the mouse is a common task, these short-cuts can be used:
* mouse('#menuItem32').click()
* mouse(100, 200).go()
* waitForEnabled('#someBtn').mouse().click()
These are useful in situations where the “normal” click() does not work - especially when the element you are clicking is not a normal hyperlink (<a href="">) or <button>.
The rare need to “double-click” is supported as a doubleClick() method:
* mouse('#myBtn').doubleClick()
Note that you can chain mouse() off an Element which can be really convenient. Refer to the section on handling drop downs for an example.
close()
Close the page / tab.
quit()
Closes the browser. You normally never need to use this in a test, Karate will close the browser automatically after a Scenario unless the driver instance was created before entering the Scenario.
html()
Get the outerHTML, so will include the markup of the selected element. Useful for match contains assertions. Example:
And match html('#eg01DivId') == '<div id="eg01DivId">this div is outside the iframe</div>'
text()
Get the textContent. Example:
And match text('.myClass') == 'Class Locator Test'
value()
Get the HTML form-element value. Example:
And match value('.myClass') == 'some value'
value(set)
Set the HTML form-element value. Example:
When value('#eg01InputId', 'something more')
attribute()
Get the HTML element attribute value by attribute name. Example:
And match attribute('#eg01SubmitId', 'type') == 'submit'
enabled()
If the element is enabled and not disabled:
And match enabled('#eg01DisabledId') == false
Also see waitUntil() for an example of how to wait until an element is “enabled” or until any other element property becomes the target value.
waitForUrl()
Very handy for waiting for an expected URL change and asserting if it happened.
For convenience, it will do a string contains match (not an exact match) so you don’t need to worry about http vs https for example. It will also return a string which is the actual URL in case you need to use it for further actions in the test script.
# note that you don't need the full url
* waitForUrl('/some/path')
# if you want to get the actual url for later use
* def actualUrl = waitForUrl('/some/path')
See waitForUrl() instead of submit(). Also see waits.
waitForText()
This is just a convenience short-cut for waitUntil(locator, "_.textContent.includes('" + expected + "')") since it is so frequently needed. Note the use of the JavaScript String.includes() function to do a text contains match for convenience. The need to “wait until some text appears” is so common, and with this - you don’t need to worry about dealing with white-space such as line-feeds and invisible tab characters.
Of course, try not to use single-quotes within the string to be matched, or escape them using a back-slash (\) character.
* waitForText('#eg01WaitId', 'APPEARED')
And if you really need to scan the whole page for some text, you can use this, but it is better to be more specific for better performance:
* waitForText('body', 'APPEARED')
waitForEnabled()
This is just a convenience short-cut for waitUntil(locator, '!_.disabled') since it is so frequently needed:
And waitForEnabled('#someId').click()
Also see waits.
waitForResultCount()
A very powerful and useful way to wait until the number of elements that match a given locator is equal to a given number. This is super-useful when you need to wait for say a table of slow-loading results, and where the table may contain fewer elements at first. There are two variations. The first will simply return a List of Element instances.
* waitForResultCount('div#eg01 div', 4)
Most of the time, you just want to wait until a certain number of matching elements, and then move on with your flow, and in that case, the above is sufficient. If you need to actually do something with each returned Element, see locateAll() or the option below.
The second variant takes a third argument, which is going to do the same thing as the scriptAll() method:
When def list = waitForResultCount('div#eg01 div', 4, '_.innerHTML')
Then match list == '#[4]'
And match each list contains '@@data'
So in a single step we can wait for the number of elements to match and extract data as an array.
waitFor()
This is typically used for the first element you need to interact with on a freshly loaded page. Use this in case a submit() for the previous action is un-reliable, see the section on waitFor() instead of submit()
This will wait until the element (by locator) is present in the page and uses the configured retry() settings. This will fail the test if the element does not appear after the configured number of re-tries have been attempted.
Since waitFor() returns an Element instance on which you can call “chained” methods, this can be the pattern you use, which is very convenient and readable:
And waitFor('#eg01WaitId').click()
Also see waits.
waitForAny()
Rarely used - but accepts multiple arguments for those tricky situations where a particular element may or may not be present in the page. It returns the Element representation of whichever element was found first, so that you can perform conditional logic to handle accordingly.
But since the optional() API is designed to handle the case when a given locator does not exist, you can write some very concise tests, without needing to examine the returned object from waitForAny().
Here is a real-life example combined with the use of retry():
* retry(5, 10000).waitForAny('#nextButton', '#randomButton')
* optional('#nextButton').click()
* optional('#randomButton').click()
If you have more than two locators you need to wait for, use the single-argument-as-array form, like this:
* waitForAny(['#nextButton', '#randomButton', '#blueMoonButton'])
Also see waits.
optional()
Returns an Element (instead of exists() which returns a boolean). What this means is that it can be chained as you expect. But there is a twist ! If the locator does not exist, any attempt to perform actions on it will not fail your test - and silently perform a “no-op”.
This is designed specifically for the kind of situation described in the example for waitForAny(). If you wanted to check if the Element returned exists, you can use the present property “getter” as follows:
* assert optional('#someId').present
But what is most useful is how you can now click only if element exists. As you can imagine, this can handle un-predictable dialogs, advertisements and the like.
* optional('#elusiveButton').click()
# or if you need to click something else
* if (exists('#elusivePopup')) click('#elusiveButton')
And yes, you can use an if statement in Karate !
Note that the optional(), exists() and locate() APIs are a little different from the other Element actions, because they will not honor any intent to retry() and immediately check the HTML for the given locator. This is important because they are designed to answer the question: “does the element exist in the HTML page right now ?”
Note that the “opposite” of optional() is locate() which will fail if the element is not present.
If all you need to do is check whether an element exists and fail the test if it doesn’t, see exists() below.
exists()
This method returns a boolean (true or false), perfect for asserting if an element exists and giving you the option to perform conditional logic, or manually fail the test.
Note that there is a karate.fail() API that may be handy when you want to fail a test after advanced / conditional checks.
And also note that instead of using the match keyword, you can use karate.match() for very advanced conditional checks.
* var buttonExists = exists('#myButton')
* var labelExists = exists('#myLabel')
* if (buttonExists && !labelExists) karate.fail('button exists but label does not')
waitUntil()
Wait for the browser JS expression to evaluate to true. Will poll using the retry() settings configured.
* waitUntil("document.readyState == 'complete'")
Note that the JS here has to be a “raw” string that is simply sent to the browser as-is and evaluated there. This means that you cannot use any Karate JS objects or API-s such as karate.get() or driver.title. So trying to use driver.title == 'My Page' will not work, instead you have to do this:
* waitUntil("document.title == 'My Page'")
Also see Karate vs the Browser.
waitUntil(locator,js)
A very useful variant that takes a locator parameter is where you supply a JavaScript “predicate” function that will be evaluated on the element returned by the locator in the HTML DOM. Most of the time you will prefer the short-cut boolean-expression form that begins with an underscore (or “!”), and Karate will inject the JavaScript DOM element reference into a variable named “_”.
Here is a real-life example:
One limitation is that you cannot use double-quotes within these expressions, so stick to the pattern seen below.
And waitUntil('.alert-message', "_.innerHTML.includes('Some Text')")
Karate vs the Browser
One thing you need to get used to is the “separation” between the code that is evaluated by Karate and the JavaScript that is sent to the browser (as a raw string) and evaluated. Pay attention to the fact that the includes() function you see in the above example - is pure JavaScript.
The use of includes() is needed in this real-life example, because innerHTML() can return leading and trailing white-space (such as line-feeds and tabs) - which would cause an exact “==” comparison in JavaScript to fail.
But guess what - this example is baked into a Karate API, see waitForText().
For an example of how JavaScript looks like on the “Karate side” see Function Composition.
This form of waitUntil() is very useful for waiting for some HTML element to stop being disabled. Note that Karate will fail the test if the waitUntil() returned false - even after the configured number of re-tries were attempted.
And waitUntil('#eg01WaitId', "function(e){ return e.innerHTML == 'APPEARED!' }")
# if the expression begins with "_" or "!", Karate will wrap the function for you !
And waitUntil('#eg01WaitId', "_.innerHTML == 'APPEARED!'")
And waitUntil('#eg01WaitId', '!_.disabled')
Also see waitForEnabled() which is the preferred short-cut for the last example above, also look at the examples for chaining and then the section on waits.
waitUntil(function)
A very powerful variation of waitUntil() takes a full-fledged JavaScript function as the argument. This can loop until any user-defined condition and can use any variable (or Karate or Driver JS API) in scope. The signal to stop the loop is to return any not-null object. And as a convenience, whatever object is returned, can be re-used in future steps.
This is best explained with an example. Note that scriptAll() will return an array, as opposed to script().
When search.input('karate-logo.png')
# note how we return null to keep looping
And def searchFunction =
"""
function() {
var results = scriptAll('.js-tree-browser-result-path', '_.innerText');
return results.size() == 2 ? results : null;
}
"""
# note how we returned an array from the above when the condition was met
And def searchResults = waitUntil(searchFunction)
# and now we can use the results like normal
Then match searchResults contains 'karate-core/src/main/resources/karate-logo.png'
The above logic can actually be replaced with Karate’s built-in short-cut - which is waitForResultCount() Also see waits.
Also see Loop Until.
Function Composition
The above example can be re-factored in a very elegant way as follows, using Karate’s native support for JavaScript:
# this can be a global re-usable function !
And def innerText = function(locator){ return scriptAll(locator, '_.innerText') }
# we compose a function using another function (the one above)
And def searchFunction =
"""
function() {
var results = innerText('.js-tree-browser-result-path');
return results.size() == 2 ? results : null;
}
"""
The great thing here is that the innnerText() function can be defined in a common feature which all your scripts can re-use. You can see how it can be re-used anywhere to scrape the contents out of any HTML tabular data, and all you need to do is supply the locator that matches the elements you are interested in.
Also see Karate vs the Browser.
retry()
For tests that need to wait for slow pages or deal with un-predictable element load-times or state / visibility changes, Karate allows you to temporarily tweak the internal retry settings. Here are the few things you need to know.
Retry Defaults
The default retry settings are:
count: 3,interval: 3000 milliseconds (try three times, and wait for 3 seconds before the next re-try attempt)- it is recommended that you stick to these defaults, which should suffice for most applications
- if you really want, you can change this “globally” in
karate-config.jslike this:configure('retry', { count: 10, interval: 5000 });
- or any time within a script (
*.featurefile) like this:* configure retry = { count: 10, interval: 5000 }
Retry Actions
By default, all actions such as click() will not be re-tried - and this is what you would stick to most of the time, for tests that run smoothly and quickly. But some troublesome parts of your flow will require re-tries, and this is where the retry() API comes in. There are 3 forms:
retry()- just signals that the next action will be re-tried if it fails, using the currently configured retry settingsretry(count)- the next action will temporarily use thecountprovided, as the limit for retry-attemptsretry(count, interval)- temporarily change the retrycountand retryinterval(in milliseconds) for the next action
And since you can chain the retry() API, you can have tests that clearly express the “intent to wait”. This results in easily understandable one-liners, only at the point of need, and to anyone reading the test - it will be clear as to where extra “waits” have been applied.
Here are the various combinations for you to compare using click() as an example.
| Script | Description |
|---|---|
click('#myId') | Try to stick to this default form for 95% of your test. If the element is not found, the test will fail immediately. But your tests will run smoothly and super-fast. |
waitFor('#myId').click() | Use waitFor() for the first element on a newly loaded page or any element that takes time to load after the previous action. For the best performance, use this only if using submit() for the (previous) action (that triggered the page-load) is not reliable. It uses the currently configured retry settings. With the defaults, the test will fail after waiting for 3 x 3000 ms which is 9 seconds. Prefer this instead of any of the options below, or in other words - stick to the defaults as far as possible. |
retry().click('#myId') | This happens to be exactly equivalent to the above ! When you request a retry(), internally it is just a waitFor(). Prefer the above form as it is more readable. The advantage of this form is that it is easy to quickly add (and remove) when working on a test in development mode. |
retry(5).click('#myId') | Temporarily use 5 as the max retry attempts to use and apply a “wait”. Since retry() expresses an intent to “wait”, the waitFor() can be omitted for the chained action. |
retry(5, 10000).click('#myId') | Temporarily use 5 as the max retry attempts and 10 seconds as the time to wait before the next retry attempt. Again like the above, the waitFor() is implied. The test will fail if the element does not load within 50 seconds. |
Wait API
The set of built-in functions that start with “wait” handle all the cases you would need to typically worry about. Keep in mind that:
- all of these examples will
retry()internally by default - you can prefix a
retry()only if you need to over-ride the settings for this “wait” - as shown in the second row
| Script | Description |
|---|---|
waitFor('#myId') | waits for an element as described above |
retry(10).waitFor('#myId') | like the above, but temporarily over-rides the settings to wait for a longer time, and this can be done for all the below examples as well |
waitForUrl('google.com') | for convenience, this uses a string contains match - so for example you can omit the http or https prefix |
waitForText('#myId', 'appeared') | frequently needed short-cut for waiting until a string appears - and this uses a “string contains” match for convenience |
waitForEnabled('#mySubmit') | frequently needed short-cut for waitUntil(locator, '!_disabled') |
waitForResultCount('.myClass', 4) | wait until a certain number of rows of tabular data is present |
waitForAny('#myId', '#maybe') | handle if an element may or may not appear, and if it does, handle it - for e.g. to get rid of an ad popup or dialog |
waitUntil(expression) | wait until any user defined JavaScript statement to evaluate to true in the browser |
waitUntil(function) | use custom logic to handle any kind of situation where you need to wait, and use other API calls if needed |
Also see the examples for chaining.
script()
Will actually attempt to evaluate the given string as JavaScript within the browser.
* assert 3 == script("1 + 2")
To avoid problems, stick to the pattern of using double-quotes to “wrap” the JavaScript snippet, and you can use single-quotes within.
* script("console.log('hello world')")
But note that you can always “escape” a quote if needed, using back-slashes:
* script("console.log('I\\'ve been logged')")
A more useful variation is to perform a JavaScript eval on a reference to the HTML DOM element retrieved by a locator. For example:
And match script('#eg01WaitId', "function(e){ return e.innerHTML }") == 'APPEARED!'
# which can be shortened to:
And match script('#eg01WaitId', '_.innerHTML') == 'APPEARED!'
Normally you would use text() to do the above, but you get the idea. Expressions follow the same short-cut rules as for waitUntil().
Here is an interesting example where a JavaScript event can be triggered on a given HTML element:
* waitFor('#someId').script("_.dispatchEvent(new Event('change'))")
When starting with _, the ES6 arrow function syntax is also supported. This is more compact, and is especially useful for expressions that do not start with the current DOM element. Here is an example of getting the “computed style” for a given element:
* match script('.styled-div', "function(e){ return getComputedStyle(e)['font-size'] }") == '30px'
# this shorter version is equivalent to the above
* match script('.styled-div', "_ => getComputedStyle(_)['font-size']") == '30px'
For an advanced example of simulating a drag and drop operation see this answer on Stack Overflow.
Also see the plural form scriptAll().
scriptAll()
Just like script(), but will perform the script eval() on all matching elements (not just the first) - and return the results as a JSON array / list. This is very useful for “bulk-scraping” data out of the HTML (such as <table> rows) - which you can then proceed to use in match assertions:
# get text for all elements that match css selector
When def list = scriptAll('div div', '_.textContent')
Then match list == '#[3]'
And match each list contains '@@data'
See Function Composition for another good example. Also see the singular form script().
scriptAll() with filter
scriptAll() can take a third argument which has to be a JavaScript “predicate” function, that returns a boolean true or false. This is very useful to “filter” the results that match a desired condition - typically a text comparison. For example if you want to get only the cells out of a <table> that contain the text “data” you can do this:
* def list = scriptAll('div div', '_.textContent', function(x){ return x.contains('data') })
* match list == ['data1', 'data2']
Note that the JS in this case is run by Karate not the browser, so you use the Java
String.contains()API not the JavaScriptString.includes()one.
See also locateAll() with filter.
driver.scriptAwait()
Only supported for type: 'chrome' - this will wait for a JS promise to resolve and then return the result as a JSON object. Here is an example:
* def axeResponse = driver.scriptAwait('axe.run()')
locate()
Rarely used, but when you want to just instantiate an Element instance, typically when you are writing custom re-usable functions, or using an element as a “waypoint” to access other elements in a large, complex “tree”.
* def e = locate('.some-div')
# now you can have multiple steps refer to "e"
* e.locate('.something-else').input('foo')
* e.locate('.some-button').click()
Note that locate() will fail the test if the element was not found. Think of it as just like waitFor() but without the “wait” part.
See also locateAll().
locateAll()
This will return all elements that match the locator as a list of Element instances. You can now use Karate’s core API and call chained methods. Here are some examples:
# find all elements with the text-content "Click Me"
* def elements = locateAll('{}Click Me')
* match karate.sizeOf(elements) == 7
* elements[6].click()
* match elements[3].script('_.tagName') == 'BUTTON'
Take a look at how to loop and transform data for more ideas.
locateAll() with filter
locateAll() can take a second argument which has to be a JavaScript “predicate” function, that returns a boolean true or false. This is very useful to “filter” the results that match a desired condition - typically a text comparison.
Imagine a situation where you want to get only the element where a certain attribute value starts with some text - and then click on it. A plain CSS selector won’t work - but you can do this:
* def filter = function(x){ return x.attribute('data-label').startsWith('somePrefix_') }
* def list = locateAll('div[data-label]', filter)
* list[0].click()
The filter function above, will be called for each Element - which means that you can call methods on it such as Element.attribute(name) in this case. Note that the JS function in this case is run by Karate not the browser, so you use the Java String.startsWith() API.
Since you can call Element.script() - any kind of filtering will be possible. For example here is the equivalent of the example above. Note the combination of “Karate JavaScript” and “JS that runs in the browser”:
* def filter = function(x){ return x.script("_.getAttribute('data-label')").startsWith('somePrefix_') }
* def list = locateAll('div[data-label]', filter)
* list[0].click()
See also scriptAll() with filter.
refresh()
Normal page reload, does not clear cache.
reload()
Hard page reload, which will clear the cache.
back()
forward()
maximize()
minimize()
fullscreen()
cookie(set)
Set a cookie. The method argument is JSON, so that you can pass more data in addition to the value such as domain and url. Most servers expect the domain to be set correctly like this:
Given def myCookie = { name: 'hello', value: 'world', domain: '.mycompany.com' }
When cookie(myCookie)
Then match driver.cookies contains '#(^myCookie)'
Note that you can do the above as a one-liner like this:
* cookie({ name: 'hello', value: 'world' }), just keep in mind here that then it would follow the rules of Enclosed JavaScript (not Embedded Expressions)
Hybrid Tests
If you need to set cookies before the target URL is loaded, you can start off by navigating to about:blank like this:
# perform some API calls and initialize the value of "token"
* driver 'about:blank'
* cookie({ name: 'my.auth.token', value: token, domain: '.mycompany.com' })
# now you can jump straight into your home page and bypass the login screen !
* driver baseUrl + '/home'
This is very useful for “hybrid” tests. Since Karate combines API testing capabilities, you can sign-in to your SSO store via a REST end-point, and then drop cookies onto the browser so that you can bypass the user log-in experience. This can be a huge time-saver !
Note that the API call (or the routine that gets the required data) can be made to run only once for the whole test-suite using karate.callSingle().
cookie()
Get a cookie by name. Note how Karate’s match syntax comes in handy.
* def cookie1 = { name: 'foo', value: 'bar' }
And match driver.cookies contains '#(^cookie1)'
And match cookie('foo') contains cookie1
driver.cookies
See above examples.
deleteCookie()
Delete a cookie by name:
When deleteCookie('foo')
Then match driver.cookies !contains '#(^cookie1)'
clearCookies()
Clear all cookies.
When clearCookies()
Then match driver.cookies == '#[0]'
dialog()
There are two forms. The first takes a single boolean argument - whether to “accept” or “cancel”. The second form has an additional string argument which is the text to enter for cases where the dialog is expecting user input.
# cancel
* dialog(false)
# enter text and accept
* dialog(true, 'some text')
driver.dialogText
After using dialog() you can retrieve the text of the currently visible dialog:
* match driver.dialogText == 'Please enter your name:'
switchPage()
When multiple browser tabs are present, allows you to switch to one based on page title or URL.
When switchPage('Page Two')
For convenience, a string “contains” match is used. So you can do this, without needing the https:// part:
* switchPage('mydomain.com/dashboard')
You can also switch by page index if you know it:
* switchPage(1)
switchFrame()
This “sets context” to a chosen frame (or <iframe>) within the page. There are 2 variants, one that takes an integer as the param, in which case the frame is selected based on the order of appearance in the page:
When switchFrame(0)
Or you use a locator that points to the <iframe> element that you need to “switch to”.
When switchFrame('#frame01')
After you have switched, any future actions such as click() would operate within the “selected” <iframe>. To “reset” so that you are back to the “root” page, just switch to null (or integer value -1):
When switchFrame(null)
screenshot()
There are two forms, if a locator is provided - only that HTML element will be captured, else the entire browser viewport will be captured. This method returns a byte array.
This will also do automatically perform a karate.embed() - so that the image appears in the HTML report.
* screenshot()
# or
* screenshot('#someDiv')
If you want to disable the “auto-embedding” into the HTML report, pass an additional boolean argument as false, e.g:
* screenshot(false)
# or
* screenshot('#someDiv', false)
The call to screenshot() returns a Java byte-array, which is convenient if you want to do something specific such as save it to a file. The usage of karate.write() here is just an example, you can use JS or Java interop as needed.
* def bytes = screenshot(false)
* def file = karate.write(bytes, 'test.png')
* print 'screenshot saved to:', file
pdf()
To create paginated pdf document from the page loaded.
* def pdfDoc = pdf({'orientation': 'landscape'})
* karate.write(pdfDoc, "pdfDoc.pdf")
highlight()
To visually highlight an element in the browser, especially useful when working in the debugger. Uses the configured highlightDuration.
* highlight('#eg01DivId')
highlightAll()
Plural form of the above.
* highlightAll('input')
timeout()
Rarely used, but sometimes for only some parts of your test - you need to tell the browser to wait for a very slow loading page. Behind the scenes, this sets the HTTP communication “read timeout”. This does the same thing as the timeout key in the driver config - but is designed so that you can change this “on the fly”, during the flow of a test.
Note that the duration is in milliseconds. As a convenience, to “reset” the value to what was initially set, you can call timeout() with no argument:
# wait 3 minutes if needed for page to load
* timeout(3 * 60 * 1000)
* driver 'http://mydomain/some/slow/page'
# reset to defaults for the rest of the test ...
* timeout()
driver.sessionId
Only applies to WebDriver based driver sessions, and useful in case you need the session id to download any test-reports / video etc.
* def sessionId = driver.sessionId
Tree Walking
The Element API has “getters” for the following properties:
parentchildren(returns an array ofElement-s)firstChildlastChildpreviousSiblingnextSibling
This can be convenient in some cases, for example as an alternative to Friendly Locators. For example, where it is easy (or you already have a reference) to locate some element and you want to use that as a “base” to perform something on some other element which may not have a unique id or css / XPath locator.
* locate('#someDiv').parent.firstChild.click()
* locate('#foo').parent.children[3].click()
Also note that locate() and locateAll() can be called on an Element, so that the “search scope” is limited to that Element and it’s children.
Looping
Looping over data is easy in Karate because of the natural way in which you can loop over JS arrays. And the API for UI testing is designed to return arrays, for example scriptAll() and locateAll() turn out to be very useful.
For example, if you had a list of rows shown on the screen, and you wanted to click on all of them, you could do this:
* def rows = locateAll('.my-table tr button')
* rows.forEach(row => row.click())
If you wanted to do multiple actions per iteration of the loop, refer to the example for handling drop downs.
Loop Until
A different kind of loop is when you need to perform an action until no more data exists. This is where the waitUntil() API comes in handy.
* def delete =
"""
function() {
if (!exists('.border-bottom div')) {
return true;
}
click('.text-end button');
}
"""
* waitUntil(delete)
How this works is as long as the function does not return a value, waitUntil() will loop. The click('.text-end button') is deleting the first row of records in the HTML. So the code above very neatly performs the loop and also exits the loop when there are no more records, and that is why we have the check for !exists('.border-bottom div').
Drop Downs
This section exists here in the documentation because it is a frequently asked question, and most drop-down “select” experiences in the wild are powered by JavaScript which makes it harder. These are cases where select will not work. Instead, most JS-powered drop-down components can be handled by using mouse().
For example, consider this HTML which is using Bootstrap:
<div class="dropdown">
<button class="btn btn-secondary dropdown-toggle" type="button" data-bs-toggle="dropdown" aria-expanded="false">
Dropdown button
</button>
<ul class="dropdown-menu">
<li><a class="dropdown-item" href="#">First</a></li>
<li><a class="dropdown-item" href="#">Second</a></li>
<li><a class="dropdown-item" href="#">Third</a></li>
</ul>
</div>
The way to handle this is in two steps, first to click on the button to show the list of items, and then to click on one of the items:
* mouse('button').click()
* mouse('a.dropdown-item').click()
Looping Over Elements
In the above example, what if we wanted to loop over each drop-down item and select each one. Here’s how we can do it. Note how we can have multiple actions within the loop.
* def list = locateAll('a.dropdown-item')
* def fun =
"""
function(e) {
mouse('button').click();
e.mouse().click();
delay(2000);
}
"""
* list.forEach(fun)
Note how we could chain the mouse() method off an Element instance, which is really convenient.
For the full working expanded example that shows all the concepts you need for looping over elements and handling drop-downs, refer to this example and the corresponding HTML.
Debugging
You can use the Visual Studio Karate entension for stepping through and debugging a test. You can see a demo video here. We recommend that you get comfortable with this because it is going to save you lots of time. And creating tests may actually turn out to be fun !
When you are in a hurry, you can pause a test in the middle of a flow just to look at the browser developer tools to see what CSS selectors you need to use. For this you can use karate.stop() - but of course, NEVER forget to remove this before you move on to something else !
* karate.stop(9000)
And then you would see something like this in the console:
*** waiting for socket, type the command below:
curl http://localhost:9000
in a new terminal (or open the URL in a web-browser) to proceed ...
In most IDE-s, you would even see the URL above as a clickable hyperlink, so just clicking it would end the stop(). This is really convenient in “dev-local” mode. The integer port argument is mandatory and you have to choose one that is not being used.
Code Reuse
You will often need to move steps (for e.g. a login flow) into a common feature that can be called from multiple test-scripts. When using a browser-driver, a call in “shared scope” has to be used. This means:
- a single driver instance is used for any
call-s, even if nested - even if the driver is instantiated (using the
driverkeyword) within a “called” feature - it will remain in the context after thecallreturns
A typical pattern will look like this:
Feature: main
Background:
* call read('login.feature')
Scenario:
* click('#someButton')
# the rest of your flow
Where login.feature would look something like:
Feature: login
Scenario:
* configure driver = { type: 'chrome' }
* driver urlBase + '/login'
* input('#username', 'john')
* input('#password', 'secret')
* click('#loginButton')
* waitForUrl('/dashboard')
There are many ways to parameterize the driver config or perform environment-switching, read this for more details.
Note callonce is not supported for a driver instance. Separate Scenario-s that can run in parallel are encouraged. If you really want a long-running flow that combines steps from multiple features, you can make a call to each of them from the single “top-level” Scenario.
Feature: main
Background:
* call read('login.feature')
Scenario:
* call read('some.feature')
* call read('another.feature@someTag')
Best-practice would be to implement Hybrid Tests where the values for the auth-cookies are set only once for the whole test-suite using karate.callSingle().
Also see Looping Over Elements.
JavaScript Function Reuse
As described in the section above on Methods - functions on the driver object will be auto-injected as variables, but the important thing to note is that this will happen only after the driver is instantiated via the driver keyword.
If you need to wrap a sequence of UI actions into a re-usable unit, JavaScript is convenient. A good example of doing this in the section on Looping Over Elements. Here, the function is declared in-line, and after the driver was instantiated.
But if you wanted to take JS function re-use to the next-level, you may choose to keep them in a separate file and follow the pattern described here. If this common feature file is called before the driver is initialized, you will need to modify the JS code to:
- get the
driverinstance usingkarate.get(). - and call methods on the
driverinstance (instead of directly)
Here is an example:
* def deleteFirstRow =
"""
function() {
var driver = karate.get('driver');
if (!driver.exists('.border-bottom div')) {
return true;
}
driver.click('.text-end button');
}
"""
You can compare the above with the example in the section on Looping Over Elements to appreciate the difference.
Locator Lookup
Other UI automation frameworks spend a lot of time encouraging you to follow a so-called “Page Object Model” for your tests. The Karate project team is of the opinion that things can be made simpler.
One indicator of a good automation framework is how much work a developer needs to do in order to perform any automation action - such as clicking a button, or retrieving the value of some HTML object / property. In Karate - these are typically one-liners. And especially when it comes to test-automation, we have found that attempts to apply patterns in the pursuit of code re-use, more often than not - results in hard-to-maintain code, and severely impacts readability.
That said, there is some benefit to re-use of just locators and Karate’s support for JSON and reading files turns out to be a great way to achieve DRY-ness in tests. Here is one suggested pattern you can adopt.
First, you can maintain a JSON “map” of your application locators. It can look something like this. Observe how you can mix different locator types, because they are all just string-values that behave differently depending on whether the first character is a “/” (XPath), “{}” (wildcard), or not (CSS). Also note that this is pure JSON which means that you have excellent IDE support for syntax-coloring, formatting, indenting, and ensuring well-formed-ness. And you can have a “nested” heirarchy, which means you can neatly “name-space” your locator reference look-ups - as you will see later below.
{
"testAccounts": {
"numTransactions": "input[name=numTransactions]",
"submit": "#submitButton"
},
"leftNav": {
"home": "{}Home",
"invoices": "{a}Invoices",
"transactions": "{^}Transactions"
},
"transactions": {
"addFirst": ".transactions .qwl-secondary-button",
"descriptionInput": ".description-cell input",
"description": ".description-cell .header5",
"amount": ".amount-cell input",
}
}
Karate has great options for re-usability, so once the above JSON is saved as locators.json, you can do this in a common.feature:
* call read 'locators.json'
This looks deceptively simple, but what happens is very interesting. It will inject all top-level “keys” of the JSON file into the Karate “context” as global variables. In normal programming languages, global variables are a bad thing, but for test-automation (when you know what you are doing) - this can be really convenient.
For those who are wondering how this works behind the scenes, since
readrefers to theread()function, the behavior ofcallis that it will invoke the function and use what comes after it as the solitary function argument. And thiscallis using shared scope.
So now you have testAccounts, leftNav and transactions as variables, and you have a nice “name-spacing” of locators to refer to - within your different feature files:
* input(testAccounts.numTransactions, '0')
* click(testAccounts.submit)
* click(leftNav.transactions)
* retry().click(transactions.addFirst)
* retry().input(transactions.descriptionInput, 'test')
And this is how you can have all your locators defined in one place and re-used across multiple tests. You can experiment for yourself (probably depending on the size of your test-automation team) if this leads to any appreciable benefits, because the down-side is that you need to keep switching between 2 files - when writing and maintaining tests.
Intercepting HTTP Requests
You can selectively re-direct some HTTP requests that the browser makes - into a Karate test-double ! This gives you some powerful options, for example you can simulate Ajax and XHR failures, or even replace entire widgets or sections of the page with “fake” HTML. The unified use of Karate test-doubles means that you can script dynamic responses and handle incoming URL, query-string and header variations. The following scenario will make this clear.
We will use this page: https://www.seleniumeasy.com/test/dynamic-data-loading-demo.html - as an example. When a button on this page is clicked, a request is made to https://api.randomuser.me/?nat=us - which returns some JSON data. That data is used to make yet another request to fetch a JPEG image from e.g. https://randomuser.me/api/portraits/women/34.jpg. Finally, the page is updated to display the first-name, last-name and the image.
{kind=link}
What we will do is intercept any request to a URL pattern *randomuser.me/* and “fake” a response. We can return JSON and even an image using a mock like this:
@ignore
Feature:
Background:
* configure cors = true
* def count = 0
Scenario: pathMatches('/api/{img}')
* def response = read('billie.jpg')
* def responseHeaders = { 'Content-Type': 'image/jpeg' }
Scenario:
* def count = count + 1
* def lastName = 'Request #' + count
* def response = read('response.json')
Refer to the Karate test-doubles documentation for details. We configure cors = true to ensure that the browser does not complain about cross-origin requests. If the request is for /api/*, the first Scenario matches - else the last one is a “catch all”. Note how we can even serve an image with the right Content-Type header. And the returned JSON is dynamic, the lastName will modify response.json via an embedded-expression.
driver.intercept()
All we need to do now is to tell Chrome to intercept some URL patterns and use the above mock-server feature-file:
Feature: intercepting browser requests
Scenario:
* configure driver = { type: 'chrome' }
* driver 'https://www.seleniumeasy.com/test/dynamic-data-loading-demo.html'
* driver.intercept({ patterns: [{ urlPattern: '*randomuser.me/*' }], mock: 'mock-01.feature' })
* click('{}Get New User')
* delay(2000)
* screenshot()
driver.intercept()is fully supported only for the driver typechrome.Playwrightsupports only urlPatterns- you can route multiple URL patterns to the same Karate mock-feature, the format of each array-element under
patternscan be found here.- the
*wildcard (most likely what you need) will match any number of characters, e.g.*myhost/some/path/* ?will match any single character\can be used as an “escape” character
- the
driver.intercept()can be called only once during aScenario, which means only one mock-feature can be used - but a mock-feature can have any number ofScenario“routes”- the
mockvalue supports any Karate file-reading prefix such asclasspath: - if you need to set up HTTP mocks before even loading the first page, you can use
about:blankfor the first URL used for thedriverinit - similar to how you can pre-set acookie().
The entire example can be found here - and here is a video. Note how the “fake” response.json is tiny compared to the “real” JSON, because we know that only a few data-elements are needed for the UI to work in this case.
The Karate regression test-suite that runs in GitHub actions (effectively our CI) - includes another example, and you can find a good explanation here.
Inspecting Intercepted Requests
The driver.intercept() API returns an object on which you can call get(variableName). This comes in useful if you want to get information on what requests were intercepted. If you really want, you can write a complex mock that calls an external API, saves the response, and returns a modified response to the browser. Since you can store “global” variables in a mock in the Background, you can save any arbitrary data or “state”, and unpack them from your main test flow. Here is an example.
First the mock. Any time we handle an incoming request, we append some JSON data to the savedRequests array. Note that requestPath and requestParams are built-in variables.
Feature:
Background:
* def savedRequests = []
Scenario: pathMatches('/api/05')
* savedRequests.push({ path: requestPath, params: requestParams })
* print 'saved:', savedRequests
* def response = { message: 'hello faked' }
And in the main UI test, note how we get the value of savedRequests, and do a normal match on it !
* def mock = driver.intercept({ patterns: [{ urlPattern: '*/api/*' }], mock: '05_mock.feature' })
* click('button')
* waitForText('#containerDiv', 'hello faked')
* def requests = mock.get('savedRequests')
* match requests == [{ path: '/api/05', params: { foo: ['bar'] } }]
Intercepting All Requests
If you use * as the urlPattern every request can be routed to the mock ! And if you use the following mock, it will actually act as a “pass-through” proxy - but with the advantage that every single request and response will be emitted to target/karate.log. You may be able to turn this into a custom “record-replay” framework, or do other interesting things. Yes, you can modify the request or response if needed !
@ignore
Feature:
Scenario:
* karate.proceed()
And here is the test script:
Feature: intercepting all requests !
Scenario:
* configure driver = { type: 'chrome' }
* driver 'about:blank'
* driver.intercept({ patterns: [{ urlPattern: '*' }], mock: 'mock-02.feature' })
* driver 'https://github.com/login'
Emulate Device
driver.emulateDevice()
Emulating a device is supported natively only by type: chrome. You need to call a method on the driver object directly:
The example below has the width, height and userAgent for an iPhone X.
And driver.emulateDevice(375, 812, 'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1')
File Upload
There are multiple options, choose the one that fits you best.
driver.inputFile()
File-upload is supported natively only by type: chrome. You need to call a method on the driver object directly. Here is an example that you can try:
* configure driver = { type: 'chrome' }
* driver 'http://the-internet.herokuapp.com/upload'
* driver.inputFile('#file-upload', 'billie.jpg')
* submit().click('#file-submit')
* waitForText('#uploaded-files', 'billie.jpg')
The driver.inputFile() can take an array or varargs as the second argument. Note how Karate is able to resolve a relative path to an actual OS file-path behind the scenes. If you want to point to a real file, use the file: prefix.
Using multipart file
This is the recommended, browser-agnostic approach that uses Karate’s core-competency as an HTTP API client i.e. multipart file.
Here is how the example above looks like:
* url 'http://the-internet.herokuapp.com/upload'
* multipart file file = { read: 'billie.jpg', filename: 'billie.jpg', contentType: 'image/jpg' }
* method post
Validation can be performed if needed on the response to this HTTP POST which may be HTML, and the karate.extract() API may come in useful.
In real-life flows, you may need to pass cookies from the browser to the Karate HTTP client, so that you can simulate any flows needed after this step.
Using Karate Robot
Karate Robot is designed for desktop application testing, but since you can click on anything in the viewport, you can achieve what you may not be able to with other automation frameworks. Here is the same example using this approach, where a couple of images need to be saved as part of the test-script:
* driver 'http://the-internet.herokuapp.com/upload'
* robot { window: '^Chrome', highlight: true }
# since we have the driver active, the "robot" namespace is needed
* robot.waitFor('choose-file.png').click().delay(1000)
* robot.input('/Users/pthomas3/Desktop' + Key.ENTER)
* robot.waitFor('file-name.png').click()
* robot.input(Key.ENTER).delay(1000)
* submit().click('#file-submit')
* waitForText('#uploaded-files', 'billie.jpg')
* screenshot()
A video of the above execution can be viewed here.
Java API
Driver Java API
You can start a Driver instance programmatically and perform actions and assertions like this:
Driver driver = Driver.start("chrome");
driver.setUrl(serverUrl + "/05");
driver.click("button");
driver.waitForText("#containerDiv", "hello world");
You can find the complete example here. Also see this explanation.
Also see the Karate Java API.
Chrome Java API
As a convenience you can use the Chrome concrete implementation of a Driver directly, designed for common needs such as converting HTML to PDF - or taking a screenshot of a page. Here is an example:
import com.intuit.karate.FileUtils;
import com.intuit.karate.driver.chrome.Chrome;
import java.io.File;
import java.util.Collections;
public class Test {
public static void main(String[] args) {
Chrome chrome = Chrome.startHeadless();
chrome.setLocation("https://github.com/login");
byte[] bytes = chrome.pdf(Collections.EMPTY_MAP);
FileUtils.writeToFile(new File("target/github.pdf"), bytes);
bytes = chrome.screenshot();
// this will attempt to capture the whole page, not just the visible part
// bytes = chrome.screenshotFull();
FileUtils.writeToFile(new File("target/github.png"), bytes);
chrome.quit();
}
}
Note that in addition to driver.screenshot() there is a driver.screenshotFull() API that will attempt to capture the whole “scrollable” page area, not just the part currently visible in the viewport.
The parameters that you can optionally customize via the Map argument to the pdf() method are documented here: Page.printToPDF .
If Chrome is not installed in the default location, you can pass a String argument like this:
Chrome.startHeadless(executable)
// or
Chrome.start(executable)
For more control or custom options, the start() method takes a Map<String, Object> argument where the following keys (all optional) are supported:
executable- (String) path to the Chrome executable or batch file that starts Chromeheadless- (Boolean) if headlessmaxPayloadSize- (Integer) defaults to 4194304 (bytes, around 4 MB), but you can override it if you deal with very large output / binary payloadsuseFrameAggregation- (Boolean) defaults tofalse. Can be enabled to aggregate multiple frames if the server sends multiple frames for a single payload.
driver.screenshotFull()
Only supported for driver type chrome. See Chrome Java API. This will snapshot the entire page, not just what is visible in the viewport.
Proxy
For driver type chrome, you can use the addOption key to pass command-line options that Chrome supports:
* configure driver = { type: 'chrome', addOptions: [ '--proxy-server="https://somehost:5000"' ] }
For the WebDriver based driver types like chromedriver, geckodriver etc, you can use the webDriverSession configuration as per the W3C WebDriver spec:
* def session = { capabilities: { browserName: 'chrome', proxy: { proxyType: 'manual', httpProxy: 'somehost:5000' } } }
* configure driver = { type: 'chromedriver', webDriverSession: '#(session)' }
Appium
Screen Recording
Only supported for driver type android | ios.
* driver.startRecordingScreen()
# test
* driver.saveRecordingScreen("invoice.mp4",true)
The above example would save the file and perform “auto-embedding” into the HTML report.
You can also use driver.startRecordingScreen() and driver.stopRecordingScreen(), and both methods take recording options as JSON input.
driver.hideKeyboard()
Only supported for driver type android | ios, for hiding the “soft keyboard”.